新闻动态
编辑:LRS
【新智元导读】研究人员通过案例研究,利用大型语言模型(LLMs)如GPT-4、Claude 3和Llama 3.1,探索了思维链(CoT)提示在解码移位密码任务中的表现;CoT提示虽然提升了模型的推理能力,但这种能力并非纯粹的符号推理,而是结合了记忆和概率推理的复杂过程。
「推理」是非常能展现「人类智能」的一项能力,需要结合现有证据和过去的经验,以逻辑和系统的方式思考某件事情,进而做出决策。
大型语言模型(LLMs)以其通用性,在多项任务上都取得了出色的性能,虽然思维链(CoT)提示已经证明了大模型具备多步推理能力,但这种能力到底来自于「抽象泛化」(abstract generalization)还是「浅层启发式」(shallow heuristics),仍然没有定论。
为了深入理解影响 CoT 推理的因素,普林斯顿大学、耶鲁大学的研究人员最近发布了一项案例研究,使用三个大模型(GPT-4、Claude 3 和 Llama 3.1)利用CoT提示来执行解码移位密码(decoding shift ciphers)的符号推理任务。

论文地址:https://arxiv.org/abs/2407.01687
文中只关注这一个简单的任务,能够系统地分析出影响 CoT 性能的三个因素:任务的预期输出(概率)、模型在预训练期间隐式学习的内容(记忆),以及数量推理中涉及的中间操作(噪声推理)。
实验结果显示,这些因素可以极大地影响模型的准确率,并且可以得出结论,CoT提示带来的性能提升,既反映了模型在推理过程中有记忆的因素,也有真实推理的概率因素。
研究方法
以往的方法在研究模型推理能力时,往往在一系列复杂的推理任务上进行评估,其中任务的多样性和复杂性可能会掩盖CoT推理背后的影响因素,所以这篇论文只关注一个相对简单的任务:使用移位密码编码的文本进行破译(deciphering text encoded with a shift cipher)。
使用移位密码(shift cipher)来编码消息的过程为,将每个字母替换为在字母表中向前移动一定数量位置(shift_level)的另一个字母;解码则为相反的操作,即向后移动。
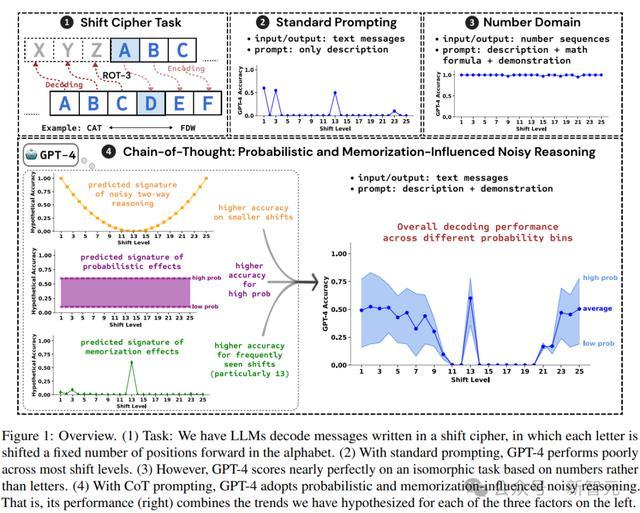
这种密码也可以称为旋转密码(rotation ciphers),过程等价于将字母表向前旋转一定数量的步rot-k,其中k对应于shift_level
例如,给定测试词「FDW」并使用rot-3加密(shift_level = 3),解码需要将每个字母向后移动3步,即F → C,D → A,W → T,最后获得解码输出「CAT」。
在实验设计时,研究人员给大模型输入一个使用移位密码编码的单词,并要求模型对文本进行解码以恢复原始单词。
任务动机
研究人员使用移位密码任务的主要出发点在于「任务复杂性」和「任务频率」之间存在明显的分离。
解密任务的复杂性也可以动态变化,移位级别(shift level)更高的密码,需要更多中间步骤,也更复杂;不同的移位级别在互联网文本中的频率也不同,在大型语言模型的训练数据中也是如此。
比如rot-13在互联网论坛中广泛用于隐藏文本,如谜题解答和剧透,而rot-3和rot-1通常用在解密教程中(rot-3也被称为凯撒密码)。
此外,移位密码有助于研究概率的影响,因为正确答案可以是任意字符串,可以很容易地调节字符串的概率,并且生成样本和正确性验证也很容易。
最重要的是,解码信息时,每个字母都是一个独立的步骤,更容易分析。
CoT在移位密码上的影响
数据
研究人员构建了一个数据集,每个单词包含7个字母(从词表中组合3个字母和4个字母的单词),用GPT-4分词器后为2个token,以控制与分词器无关的因素。
使用GPT-2计算对数概率,用句子「The word is "WORD"」的对数概率减去「The word is」的对数概率,然后把单词按其对数概率评分,并按降序排列。
通过选择等距的对数概率值作为中心,形成了五个区间,其中区间1具有最高的概率,区间5具有最低的概率,再手动检查了数据集中的单词,并进行了筛选,以确保没有使用不恰当的单词,其中每个区间包含150个单词。
数据集中总共包含150个样本,划分为两个子集:1)包含100个单词以评估GPT-4;2)包含50个单词,用于评估拟合到GPT-4在100个单词子集上表现的逻辑回归模型。
最后在1-25移位级别上生成来自5个概率区间的单词的移位密码编码版本,作为模型的输入;评估只运行一次,基于100个样本报告准确率。
评估提示
研究人员使用多种不同的提示对数据集的性能进行了评估:
1. 标准(standard)提示,只有任务描述和演示但没有推理步骤的提示;

2. 文本思维链(Text-CoT),使模型逐个字母解码消息。

要想正确得到推理步骤,模型必须在预训练期间学会字母表。
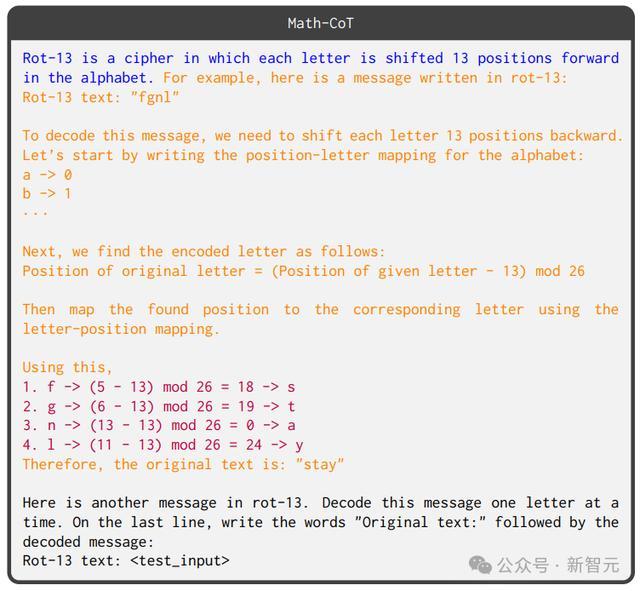
3. 数学思维链(Math-CoT),模型需要将每个字母转换为数字,然后通过数字应用算术来执行移位,再将结果转换回字母;提示中还指定了字母和位置之间的映射。
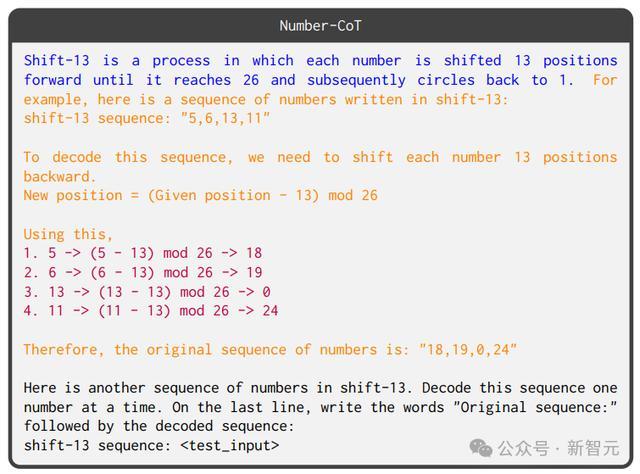
4. 数字序列思维链(Number-CoT),该任务基于数字域(即输入和输出是数字序列),与移位密码同构;推理需要对数字序列中的输入元素应用算术运算以获得相应的输出序列。
实验结果
研究人员使用了开源和闭源模型进行实验:GPT-4(gpt-4-0613),Claude 3(claude-3-opus-20240229),以及Llama-3.1-405B-Instruct,其中温度设置为0,并将max_new_tokens设置为200。
在使用标准提示时,GPT-4在大多数移位级别上的准确率为零,但当使用文本CoT时,其准确率大幅提升(平均准确率达到32%),跟以前的研究结果相同,即CoT对移位密码很有帮助,但仍然远非完美;但在使用数字CoT时,GPT-4的表现结果几乎达到了完美。
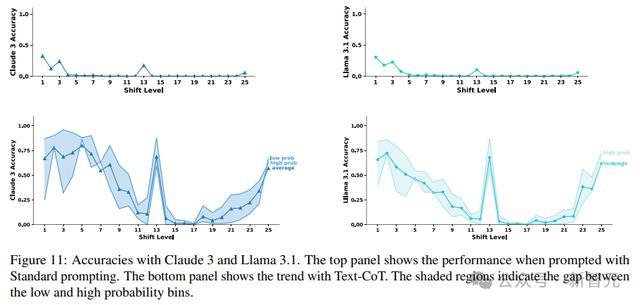
上述结果显示,如果CoT提示中用到的是符号推理,那GPT-4的推理能力就会很完美;而事实上没有得到完美分数,也表明了CoT推理并非纯粹的符号推理。
尽管如此,CoT也很明显优于标准提示,所以CoT推理不太可能仅仅是简单的记忆。
如果CoT推理既不是简单的记忆也不是纯粹的符号推理,那会是什么?
推理过程分解
研究人员考虑了大型语言模型(LLMs)可能采用的四种推理过程:
1. 符号推理(Symbolic reasoning)是使用离散的、确定性的推理规则。移位密码可以通过简单的符号算法完美解码,因此一个使用完全系统化推理的系统应该达到100%的准确率。
2. 噪声推理(Noisy reasoning)类似于符号推理,但增加了噪声,导致推理过程中每个中间操作出错的可能性。如果系统使用噪声推理,那应该看到随着需要执行的操作数量的增加,准确率会下降;移位密码可以测试出这种可能性:通过改变移位级别,可以调节每个推理步骤中需要执行的操作数量,并观察准确率是否相应变化。
3. 记忆(Memorization)策略,模型可以记住在预训练中遇到的任务,但无法泛化到新任务。如果LLMs所做的只是记忆,应该看到在预训练中经常遇到的情况比那些不经常遇到的任务表现更好。
之前有研究表明,13是自然语料库中最常见的移位级别,在一些网络社区中很常见。
4. 概率推理(Probabilistic reasoning)将任务框架为选择给定输入下最可能的输出,推理会受到输出的先验概率的影响,概率推理器应该随着正确答案的先验概率增加,准确率也会有所提升。
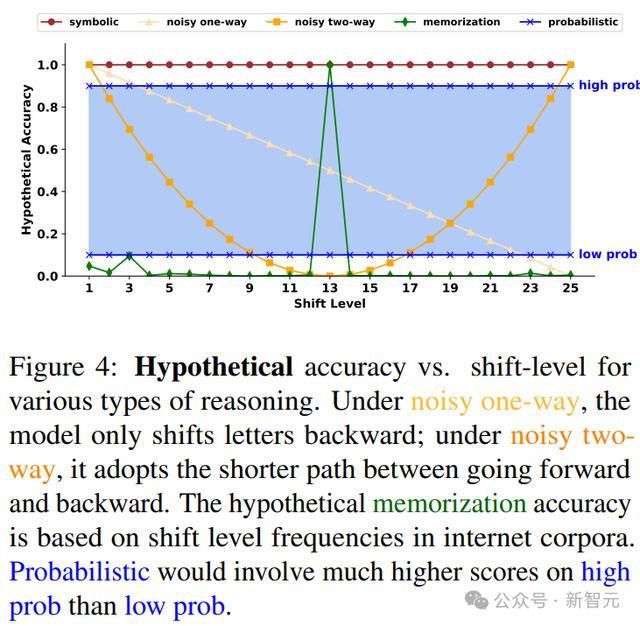
对比假设准确率,研究人员发现,随着移位级别的增加,准确率通常会下降,代表LLM在执行噪声推理,并且是双向噪声推理,模型可以对字母进行向前或向后的移位来解码消息,例如,向后移动25个字母和向前移动1个字母相同,但后者的中间步骤更少;双向性质的具体表现为,当移位级别从20变为25时,准确率会增加。
其次,模型进行概率推理的证据是,准确率在最高概率区间(区间1)远高于最低概率区间(区间5),其中「高概率」大多为常见的单词,如{'mariner', 'shrines', 'paywall', ...},而「低概率」的情况大多是无意义的字母序列,如{'xcbrouw', 'jsxrouw', 'levjspx', ...}。
最后,虽然移位级别13比其他移位级别需要更多的推理步骤,但移位级别13上的准确率存在一个峰值,代表模型执行了记忆(13是自然语料库中最常见的移位级别)。
参考资料:
https://arxiv.org/abs/2407.01687
上一篇:没有了
下一篇:没有了